L4Ka::Pistachio PowerPC Performance
page maintained by Joshua LeVasseur (jtl ∂does-not-exist.ira uka de)
Summary
All performance measurements were collected from a 500 MHz IBM 750 processor, on an Apple Pismo PowerBook, using the initial Pistachio release.
| performance metric | cycles | instructions |
|---|---|---|
| empty system call | 51.73 | 27.17 |
| address space switch | ~40 | ~24 |
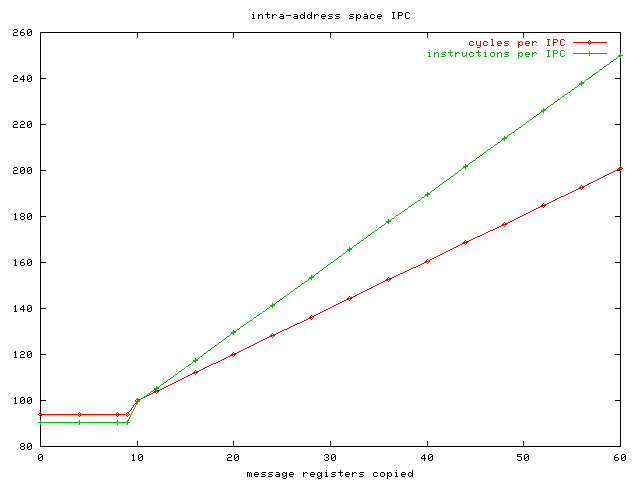
| intra-address space IPC | 93.94 | 90.35 |
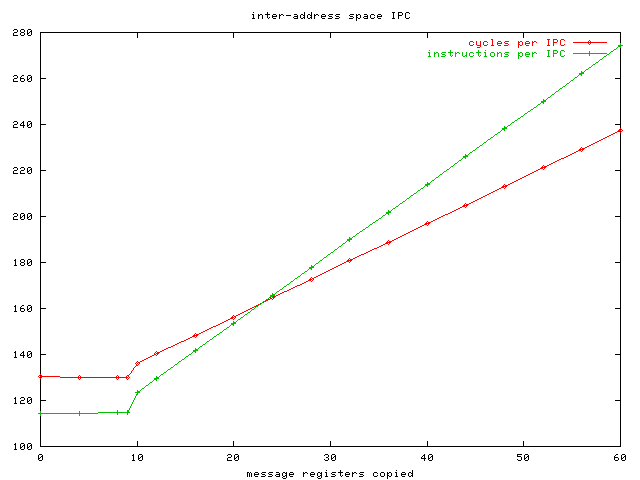
| inter-address space IPC | 130.34 | 114.51 |
- empty system call
- Reflects the number of cycles necessary to execute a specific system call handler. It includes: entering the kernel, jumping to the system call handler, enabling virtual addressing, saving and restoring user state, and returning to user mode.
- address space switch
- The cost of switching the user address space, a three-gigabyte section of the entire address space. The remaining gigabtye remains constant, and is dedicated to the kernel. The address space switch must change twelve segement registers to point at the address space ID of the new address space. The cycles-per-instruction for the address space are fairly high, due to a pipe-flush for each segment register update.
- intra-address space IPC
- An intra-address space IPC transfers a message of 0 to 10 message registers from a source thread to a destination thread. The threads live within the same address space.
- inter-address space IPC
- The inter-address space IPC transfers a message of 0 to 10 message registers from a source thread to a destination thread. The threads reside in separate address spaces.
IPC
Note: be weary of comparing IPC performance between processor architectures. The various L4Ka::Pistachio architecture ports diverge slightly in IPC fast path functionality. The implementation choices behind an IPC fast path can adversely effect system-wide performance.
The scourge of the IPC path performance is the set of system instructions which flush the pipe. The IPC path attempts to minimize the pipe flushes.
The following graphs show incremental costs for transferring larger messages of untyped registers.