L4Ka::Pistachio/ia32 Performance
The performance measurements were performed on the following system configuration:
- Dual Intel Pentium III, 800MHz (Family 6, Model 8, Stepping 10)
(16K L1 DCache, 16K L1 ICache, 256K L2 Cache) - ASUS CUR-DLS ACPI BIOS Rev. 1012
- 768MB 133MHz ECC SDRAM
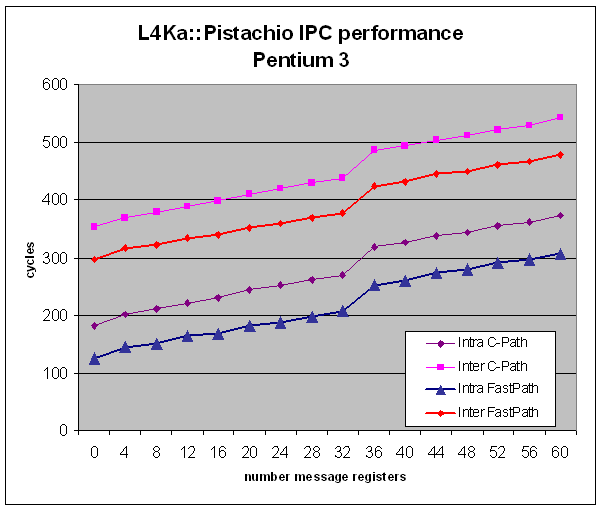
The following graph shows incremental costs for transfering larger messages of untyped message registers. The FastPath is a hand-optimized assembly IPC path covering only untyped message registers. The performance measurements were performed using the pingpong benchmark with all kernel debug features disabled, the kernel was compiled with GCC 3.2.2.
The benchmark gives a first aproximate overhead of 55 cycles for the C code path. It also clearly shows a 170 cycles performance penalty due to context switching and for re-populating the TLB. The TLB working set includes at least 5 pages (and will therefore lead to at least 5 TLB misses): code, stack, data, UTCB and KIP.
Please note that these performance numbers are measured on a not yet fully optimized kernel, and therefore should be interpreted as a first performance indicator only.